Machine Learning Fundamentals
Machine Learning (ML) on the edge is not merely "ML in a smaller box"—it is a specialized engineering discipline defined by extreme resource constraints. While traditional Cloud ML assumes the luxury of virtually unlimited compute (GPUs), memory (Terabytes) and power (Grid-connected), TinyML (Tiny Machine Learning) operates in a world of scarcity.
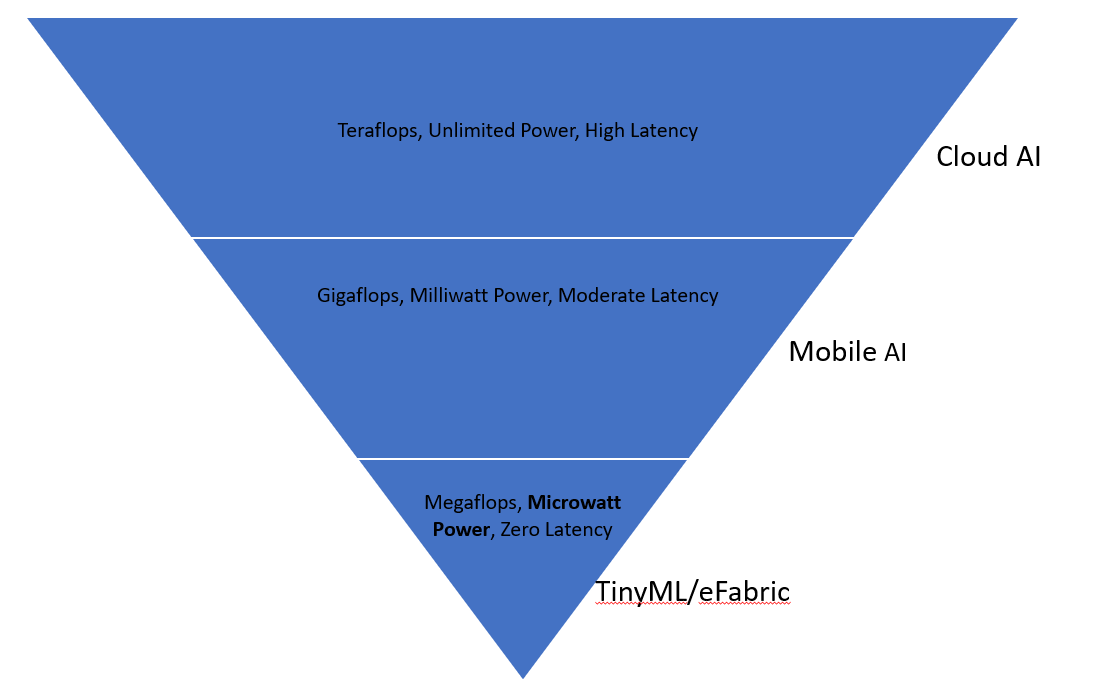
The TinyML Paradigm
At its core, TinyML is the art and science of performing complex mathematical operations—specifically deep neural network inference—within the strict physical confines of microwatt-scale silicon. For a developer, this means every byte of RAM and every clock cycle of the processor is a precious resource that must be managed with surgical precision.
“The goal of TinyML isn't just accuracy; it’s maximizing Intelligence per Microwatt. In this ecosystem, power is the primary constraint.”
To succeed at this scale, eFabric™ focuses on three technical pillars that every developer must understand:
Deterministic Inference
Unlike cloud systems where response times can fluctuate based on network traffic or server load, eFabric™ ensures that every decision made on the chip happens within a fixed, predictable time window. This Deterministic Inference is critical for real-time applications like automotive safety or industrial fault detection, where a delay of even a few milliseconds is unacceptable.
Compute Density
In the microwatt world, we measure success by how much "intelligence" we can pack into a square millimeter of silicon. By maximizing Compute Density, eFabric™ allows complex neural networks to run on chips that are physically smaller than a fingernail, without sacrificing accuracy or increasing heat dissipation.

Silicon-Level Optimization
Rather than running a generic software layer on top of a processor, eFabric™ performs Silicon-Level Optimization. It maps the mathematical neurons of your model directly to the specialized hardware gates of the Neural Decision Processor (NDP). This "hardware-native" execution is what allows our models to consume 1000x less power than a standard microcontroller.
“Optimization begins at the architecture level. Before you train, ensure your layer count aligns with the memory specs of the TML120 module.”
Why eFabric™ is a Game-Changer?
Traditionally, shrinking a model to fit on a chip required a deep understanding of quantization, pruning and assembly-level optimization. eFabric™ abstracts this complexity, acting as a high-performance compiler that translates high-level intelligence into a form that ultra-low-power chips can execute natively.
This section breaks down the core mechanics of how eFabric™ processes intelligence, moving from the mathematical foundations to the specialized hardware execution that makes "Always-On" possible.