エッジのためのニューラルネットワーク基礎
概念的なデータセットから機能するエッジデバイスへの旅は、視点の根本的なシフトから始まります。計算リソースが事実上無限のクラウドの弾力性に慣れた開発者は、TinyMLの固定リソースの現実に適応する必要があります。この環境では、アルゴリズムの効率はその精度だけでなく、シリコンフットプリントとワットあたりの計算効率によって測定されます。
この移行は開発者の旅の最も重要なフェーズを表しています。従来の機械学習フレームワークはモデルとマシンの間にある程度の分離を許可しますが、eFabric™はハードウェア対応設計哲学を要求します。マイクロワットスケールを達成するには、汎用計算のオーバーヘッドを取り除き、シリコンネイティブ実行に向かう必要があります。これにより、モデルを切り離されたソフトウェアロジックではなく、物理回路の生きた部分として扱う必要があります。
eFabric™のコンテキストでは、ニューラルネットワークは単なる数学的抽象概念ではなく、シリコンゲート上での実行に最適化された精密に設計された計算グラフです。エッジ開発者にとって、レイヤーと重みがどのようにハードウェアパフォーマンスに変換されるかを理解することが、成功する製品を構築するための鍵です。
レイヤー、ニューロン、重み:入門
従来のコンピューティングでは、ロジックは明示的な「if-then」命令によって定義されます。eFabric™ エコシステムでは、ロジックは創発的—ニューラルネットワークのアーキテクチャ内に保存されています。開発者にとって、ネットワークは生のセンサーデータを高信頼度の分類に精錬するための洗練されたフィルターとして機能する一連の計算レイヤーです。
計算の構成要素
効率的なモデルを構築するには、ネットワークのアーキテクチャの3つの基本コンポーネントを理解する必要があります:
-
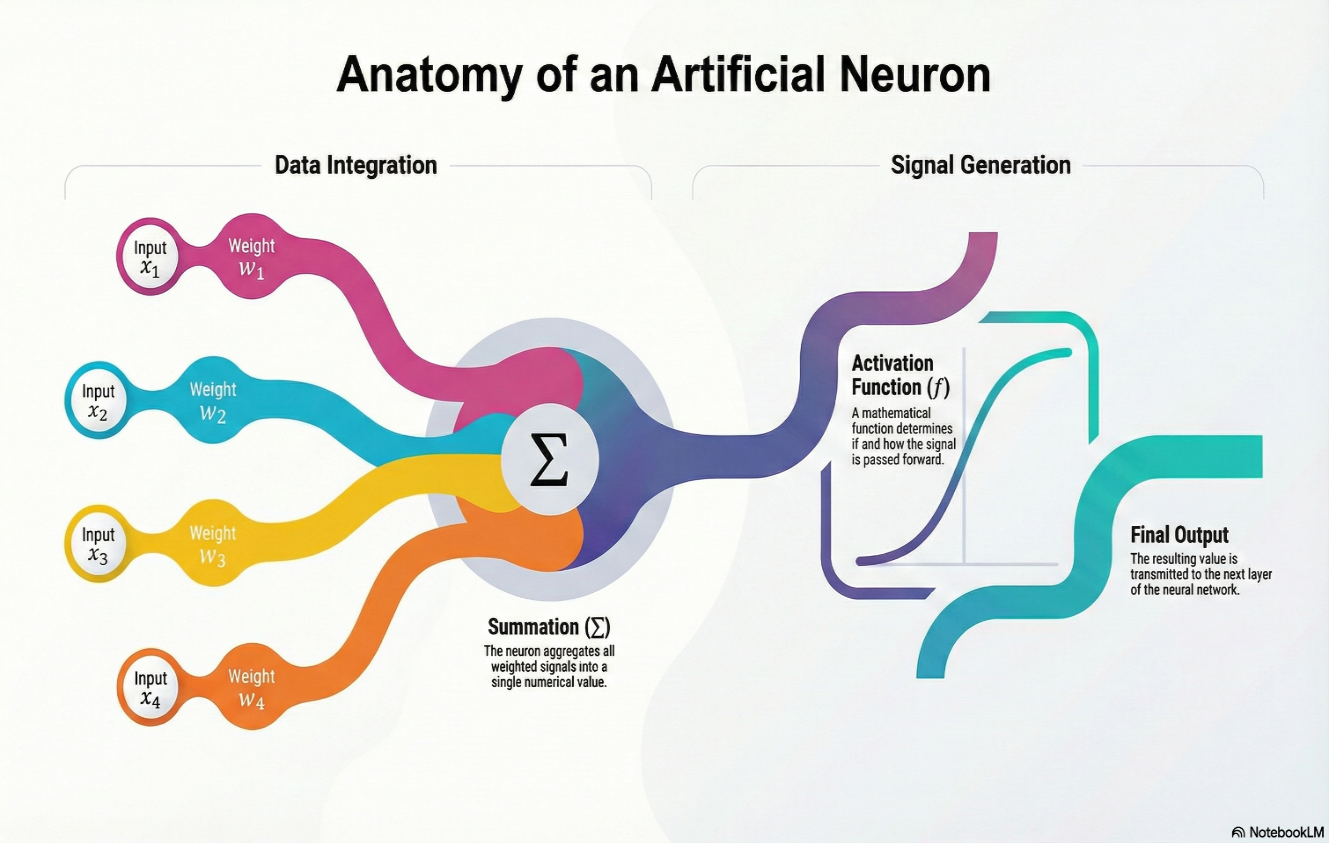
ニューロン(処理ユニット): ニューロンを数学的関数と考えてください。複数の入力を受け取り、その加重和を計算し、活性化関数(ReLUやSigmoidなど)を適用して出力を決定します。シリコンネイティブ実行では、これらのニューロンはNDP内の特定の物理ロジックゲートにマッピングされ、最大のエネルギー効率を確保します。
-
重み(学習済みメモリ): 重みはモデルのインテリジェンスの核心です。ニューロン間の接続の「強度」を表します。eFabric™ ファクトリーでの訓練フェーズ中に、プラットフォームはこれらの重みを何十億回も調整し、ネットワークが例えば「セキュリティアラーム」の音を「バックグラウンドの雑音」から区別できるようになります。
eFabricでは、重みはInt8量子化を使用して最適化されています。つまり、各重みは4バイトの浮動小数点数ではなく1バイトとして保存され、メモリフットプリントが大幅に削減されます。
必ずしも8ビットとは限りません。現在のSyntiantのNDPシリーズをターゲットにするために行っていますが、他のものは16ビットの規定を持っている可能性があるため、ターゲットハードウェアによって異なります。
-
バイアス(閾値調整器): バイアスはニューロンの入力に追加される余分なパラメータです。活性化関数を左右にシフトさせ、特定の「信頼度閾値」が満たされた場合にのみ検出をトリガーするために必要な柔軟性をモデルに提供します。
階層的な構造
eFabric™ ファクトリー内で作成されるすべてのモデルは、生データを論理的な決定に変換するレイヤーで構成されています。
-
入力レイヤー(感覚的ゲートウェイ): ここで生のデジタル信号が「ファクトリー」に入ります。このレイヤーはデジタル化された信号を受け取ります—16kHzの音声PCMデータや3軸アクセロメーターの読み取りなど。TinyMLでは、入力サイズは決定論的推論を確保するために厳密に固定されています。入力レイヤーはデータが処理のために正しい形状であることを確保します。
-
隠れレイヤー(特徴抽出とロジック): これがモデルの「脳」です。これらのレイヤーは重みによって接続されたニューロンで構成されています。
-
重みはネットワークの「メモリ」として機能し、ニューロン間の接続の強度を決定します。
-
訓練中に、eFabric™はこれらの何百万ものパラメータを微調整して特定の「シグネチャ」を識別します(例:サイレンの固有の調波パターン)。
eFabricはSyntiant® NDPに最適化された専用レイヤーを使用します:
- 畳み込みレイヤー(CNN): 空間的または時間的パターンに優れています(音の「形状」を見つける)。
- 全結合レイヤー: 高レベルの特徴が組み合わされ、入力の複雑な理解を形成します。
-
「モデルの深さ対電力:隠れレイヤーを追加するとインテリジェンスが増しますが、レイテンシと電力消費も増加します。eFabric リソース推定器を使用して「スイートスポット」を見つけてください。」
- 出力レイヤー(決定エンジン): 最終的な目的地です。このレイヤーは確率スコアを生成します。「Always-On」キーワードモデルでは、これはウェイクワードが聞こえた信頼レベルを表す単一のニューロンかもしれません(0から1の間の値を提供する単一の出力ニューロン、マッチの確率を表す)。
- 動画提案。内容: 「キーワード」(「Hey eFabric」など)が波形として入力レイヤーに入り、隠れレイヤーの特定のニューロンを照らし、出力レイヤーで「マッチが見つかりました」信号をもたらす30秒のアニメーション。
深掘り:インテリジェンスのエンジン
畳み込みニューラルネットワーク(CNN):パターン検出器
エッジAIの世界では、CNNは空間的・時間的特徴抽出のための主要ツールです。画像処理と関連付けられることが多いですが、eFabric™では、スペクトログラム(音の視覚的表現)と複雑なセンサーパターンを分析するための標準と見なされています。
-
動作原理(スライディングウィンドウ): CNNは入力データをスライドする「フィルター」または「カーネル」を使用します。数学的な畳み込みを実行してローカルパターンを識別します—ガラスの破損の周波数の急激な上昇やモーター振動の特定のリズミカルなパルスなど。
-
空間的階層: CNNは初期レイヤーで単純なパターン(エッジや周波数など)を見つけ、それを深いレイヤーで複雑な概念(「ウェイクワード」など)に組み合わせるように構造化されています。
-
eFabric™ の最適化: プラットフォームは可能な場合、深度方向分離可能畳み込みを使用します。この技術はパラメータと計算の数を大幅に削減し、高性能なCNNをTML120モジュールのマイクロワット電力予算内で実行できるようにします。
「データに「ローカル相関」がある場合にCNNを使用してください。1つのデータポイントとその隣接するものとの関係が高い場合(隣接するピクセルや連続した音声サンプルなど)、CNNが最も効率的な選択です。」
再帰型ニューラルネットワーク(RNN):順序メモリ
CNNがデータの「形状」を見つけることが得意である一方、RNNは時間と順序を理解することが得意です。これらは「Always-on」監視に不可欠であり、1秒前に何が起こったかのコンテキストが今行われている決定に重要です。
-
フィードバックループ: データが前方にのみ流れる標準ネットワークとは異なり、RNNは「隠れ状態」を持ち、メモリとして機能します。前のステップの出力を現在のステップにフィードバックします。
-
Gated Recurrent Units(GRU)とLSTM: eFabric™はGRUなどの高度なRNNバリアントをサポートします。これらは「ゲート」を使用してどの情報を記憶し、どれを忘れるかを決定し、トリガーイベントを待つ間にバックグラウンドノイズに圧倒されないようにします。
-
ユースケース–順序ロジック: ジェスチャー認識モデル(例:「ダブルタップ」)では、RNNを使用してモデルがタップ1 -> ポーズ -> タップ2の順序を2つの無関係な衝撃ではなく単一のイベントとして見るようにします。
シリコンネイティブマッピング:NDPでのCNN対RNN
eFabric™がターゲットとするSyntiant® Neural Decision Processorはこれらのアーキテクチャをゲートレベルで異なる方法で処理するために独自に設計されています:
| 機能 | CNN実行 | RNN/GRU実行 |
|---|---|---|
| ハードウェアパス | 高速フィルタリングのための並列化されたMAC(乗算累算)ユニット。 | 「時間メモリ」を維持するための専用フィードバックレジスタ。 |
| 最適な用途 | 特徴抽出、キーワードスポッティング、画像分析。 | 順序モデリング、ジェスチャー検出、長期異常追跡。 |
| 効率のヒント | カーネルを小さく(3x3または1x3)保ち、計算密度を最大化する。 | eFabric™ではLSTMよりGRUを使用し、同様の精度でメモリフットプリントを30%削減。 |
CNNとRNNがモデルの構造的インテリジェンスを提供する一方、それらは最初にエッジハードウェアの電力予算を超える高精度の計算を使用して構築されています。これらの「エンジン」を強力なワークステーションからマイクロワットスケールのNeural Decision Processorに移動するには、モデル量子化の科学を適用する必要があります。
深掘り:量子化の数学
eFabric™ エコシステムでは、最も重要な数学的変換は、モデルをワークステーションの高精度の世界(32ビット浮動小数点)からTML120モジュールのリソース制約された世界(8ビット整数)に移動する際に発生します。このプロセスは量子化として知られており、TinyML効率の礎石です。
- 量子化とは何か? モデルの精度を32ビットから8ビットに「圧縮」するプロセスです。
- メリット: これにより、モデルサイズが4倍削減され、推論速度が大幅に向上します。元の精度をほぼ維持しながら。
- eFabricの役割: プラットフォームは量子化対応訓練(QAT)を実行し、モデルが精度を低下させることなく精度が低い場合でも「学習」し、手動変換に一般的な「精度低下」を防ぎます。
線形量子化数式
最も単純なレベルでは、量子化は実数値浮動小数点数(x)とその8ビット整数表現(q)の間の線形マッピングです。これを達成するために、アフィンマッピング数式を使用します:
ここで:
- q(量子化値): 結果として得られる8ビット整数(通常-128から127の範囲)。
- x(浮動小数点値): 元の高精度の重みまたは活性化。
- S(スケール): 実数値の範囲を「縮小」する正の浮動小数点数。
- Z(ゼロポイント): 実数値0.0が正確に量子化整数にマッピングされることを確保する整数。パディングやReLU活性化関数などの操作にとって重要です。
スケール(S)とゼロポイント(Z)の計算
eFabric™ モデルのすべてのレイヤーについて、プラットフォームは最適なSとZを決定する必要があります。これは重みまたは活性化のダイナミックレンジ[min, max]を分析することで行われます:
開発者にとって、目標は量子化エラー(元の値と量子化された値の差)を最小化することです。ダイナミックレンジが広すぎると、8ビットグリッドの「解像度」が粗くなり、モデルの精度が低下します。
課題:クリッピングと精度損失
値xがレイヤーの[min, max]範囲外に落ちると、最も近い量子化境界(q_minまたはq_max)に「クリップ」されます。
- 飽和: クリッピングが多すぎると、モデルが微妙な特徴を区別する能力を失う「フラット」なモデルになります。
- 丸め誤差: round()関数によって導入される小さなエラーが深いレイヤー全体に蓄積し、最終的な推論結果をシフトさせる可能性があります。
eFabric™ ソリューション:量子化対応訓練(QAT)
多くのプラットフォームが訓練後量子化(PTQ)—モデルがすでに訓練された後に量子化する—を使用する一方、eFabric™は**量子化対応訓練(QAT)**を活用します。
QATが数学的にどのように異なるか:
eFabric™ ファクトリーでの訓練フェーズ中に、プラットフォームはモデルがまだFloat32状態にある間に「Int8効果」をシミュレートします。計算グラフに**「偽量子化」**ノードを導入します。
- 結果: モデルは丸め誤差とクリッピングエラーを補正するために重みを調整することを「学習」します。
- 優位性: QATは通常、標準的な量子化で失われた精度の98〜100%を回復し、「赤ちゃんの泣き声」または「ウェイクワード」モデルが超低電力シリコン上でも堅牢に維持されることを確保します。
[動画提案:量子化シフト] 滑らかで高解像度の波(Float32)がステップ状のピクセル化されたグリッド(Int8)でオーバーレイされる60秒の技術的な視覚化。eFabric QATプロセスが実行されると、「ピクセル」がシフトして再整列し、元の波の形を完璧に模倣します。
パターン認識のための教師あり学習
eFabric™ エコシステムでは、インテリジェンスはプログラムされません;学習されます。教師あり学習は、ノイジーな実世界のデータの複雑なパターンを認識するようにモデルを訓練するために使用する特定の機械学習パラダイムです。
「教師-生徒」モデル
その核心において、教師あり学習は入力データ(例:音声サンプル)と対応するグラウンドトゥルースラベル(例:「キーワード」または「バックグラウンド」)の両方を含むデータセットを使用してニューラルネットワークを訓練することを含みます。
- データラベリング: eFabricが学習するためには、何千もの例を「見せ」られる必要があります。ガラス破損検出器を構築している場合、実際のガラスが割れるサンプル(ポジティブサンプル)とファン、テレビ、音声などの典型的な家庭のノイズのサンプル(ネガティブサンプル)を提供する必要があります。
- 特徴マッピング: プラットフォームは数学的特徴(以前に議論したスペクトログラムなど)を抽出してこれらのラベルにマッピングします。
- 目的関数: 訓練中に、モデルは予測を行います。「サイレン」を「音声」と誤って識別した場合、eFabric™ ファクトリーはロス関数を使用してエラーを計算します。重みはその後、このエラーを最小化するためにバックプロパゲーションを介して調整されます。
多次元空間でのパターン認識
開発者にとって、教師あり学習は「境界」を引く方法として視覚化すると役立ちます。
- 決定境界: 1つの軸が「周波数」でもう1つが「持続時間」のグラフを想像してください。ニューラルネットワークは「キーワードA」を他のすべての音から分離する数学的な線を引くことを学習します。
- 汎化: 成功したeFabricモデルはアップロードした特定のクリップを単に記憶するのではなく、汎化します。パターンの本質を学習して、異なる人によって話されたり、騒がしい部屋でキーワードを認識できるようにします。
「高性能なエッジモデルには堅牢な「バックグラウンド」または「ノイズ」データのセットが必要です。多様なネガティブサンプルのセットなしに、モデルは偽陽性—実際のイベントが発生していないのにアクションをトリガーする—に苦労します。」
エッジでの推論対訓練
TinyMLに初めて触れる人にとってよくある混乱は、「学習」対「決定」の物理的な場所です。eFabric™ ワークフローでは、効率を最大化するためにこの2つの段階は厳密に切り離されています。
訓練:重い作業(クラウドサイド)
訓練は大規模なデータセットを何百万回も繰り返す計算集約的なプロセスです。
- 場所: eFabric™ クラウドファクトリーで行われます。
- 計算: 高性能GPUまたはTPU。
- 目標: 「試行錯誤」(バックプロパゲーション)を通じてモデルの重みとバイアスを最適化します。
- 出力: 高精度(Float32)の訓練済みモデル。
推論:決定(シリコンサイド)
推論は訓練されたモデルがハードウェアにデプロイされ、リアルタイムの決定を行う「ライブ」フェーズです。
- 場所: Syntiant® NDP(Neural Decision Processor)上でローカルに。
- 計算: 超低電力シリコンゲート。
- 目標: 「フォワードパス」を実行—新しい未見のセンサーデータを取得し、ミリ秒で分類スコアを生成します。
- 出力: シンプルなトリガー信号(例:「イベント検出」)。
なぜエッジでは「推論のみ」なのか?
マイクロワットスケールを達成するために、TML120モジュールは決定論的推論のために設計されています。複雑な「学習」回路をチップから取り除くことで、電力消費を1000倍削減します。チップはデプロイ後に「考えを変えたり」「新しいことを学んだり」しません;与えられた最適化・量子化されたパターンを絶対的な精度とゼロのレイテンシで実行します。
技術的優位性:ハードウェアネイティブ実行
モデルを実行するために「ソフトウェアインタープリタ」(TensorFlow Lite Microなど)を使用する汎用マイクロコントローラーとは異なり、eFabric™はニューラルネットワークをNDPのシリコンロジックに直接マッピングします。
- ゼロオーバーヘッド推論: モデルがハードウェアのネイティブフローに「焼き込まれて」いるため、次の命令を「検索」するCPUはありません。これがマイクロワットスケールの電力消費の秘密です。
- メモリ常駐: eFabric™では、モデル全体がメモリ常駐になるように設計されています。TML120モジュールのわずかなオンチップRAM内に留まり、外部メモリチップへのデータ移動の高い電力コストを排除します。