機械学習の基礎
エッジでの機械学習(ML)は単なる「小さなボックスに入ったML」ではなく、極端なリソース制約によって定義される専門的なエンジニアリング分野です。従来のクラウドMLが事実上無制限の計算(GPU)、メモリ(テラバイト)、および電力(グリッド接続)の贅沢を前提とする一方、TinyML(タイニーML)は不足の世界で動作します。
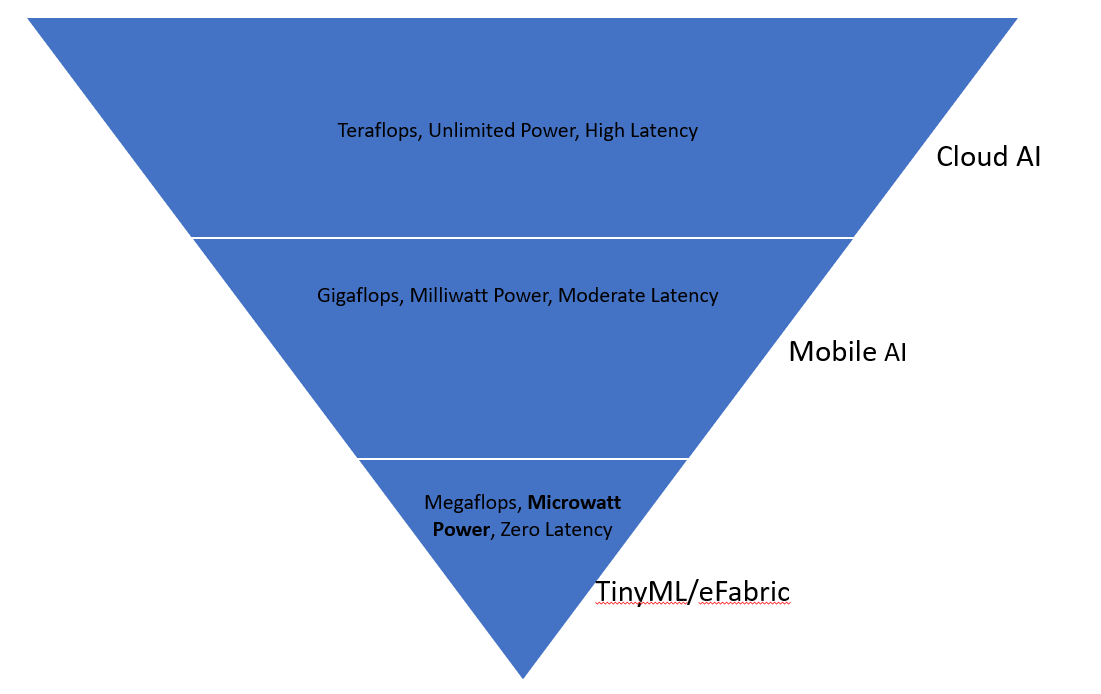
TinyMLパラダイム
その核心において、TinyMLはマイクロワットスケールのシリコンの厳しい物理的制約内で複雑な数学的演算、特にディープニューラルネットワーク推論を実行する芸術と科学です。開発者にとって、これはRAMのすべてのバイトとプロセッサのすべてのクロックサイクルが外科的精度で管理されなければならない貴重なリソースであることを意味します。
「TinyMLの目標は単に精度ではなく、マイクロワットあたりのインテリジェンスを最大化することです。このエコシステムでは、電力が主要な制約です。」
このスケールで成功するために、eFabric™はすべての開発者が理解しなければならない3つの技術的柱に焦点を当てています:
決定論的推論
クラウドシステムとは異なり、応答時間はネットワークトラフィックやサーバーの負荷によって変動する可能性がありますが、eFabric™はチップ上で行われるすべての決定が固定した予測可能な時間窓内で発生することを確保します。この決定論的推論は、数ミリ秒の遅延でさえ許容されない自動車の安全性や産業用故障検出などのリアルタイムアプリケーションにとって重要です。
計算密度
マイクロワットの世界では、シリコンの1平方ミリメートルにどれだけの「インテリジェンス」を詰め込めるかで成功を測ります。計算密度を最大化することで、eFabric™は複雑なニューラルネットワークを爪よりも物理的に小さいチップで、精度を犠牲にしたり熱放散を増やしたりすることなく実行できます。

シリコンレベルの最適化
プロセッサの上に汎用ソフトウェアレイヤーを実行する代わりに、eFabric™はシリコンレベルの最適化を実行します。モデルの数学的ニューロンをNeural Decision Processor(NDP)の専用ハードウェアゲートに直接マッピングします。この「ハードウェアネイティブ」実行により、標準的なマイクロコントローラーと比較して1000倍少ない電力を消費できます。
「最適化はアーキテクチャレベルから始まります。訓練前に、レイヤー数がTML120モジュールのメモリ仕様と一致することを確認してください。」
eFabric™はなぜゲームチェンジャーなのか?
従来、モデルをチップに収まるように縮小するには、量子化、プルーニング、アセンブリレベルの最適化の深い理解が必要でした。eFabric™はこの複雑さを抽象化し、高レベルのインテリジェンスを超低電力チップがネイティブに実行できる形式に変換する高性能コンパイラーとして機能します。
このセクションでは、eFabric™がインテリジェンスをどのように処理するかの核心メカニズムを、数学的基礎から「Always-On」を可能にする専門的なハードウェア実行まで詳述します。